지난 포스팅에 이어서 이번에는 지난 포스팅에서 추출한 이미지 파일을 읽어와서 이미지 안에 있는 글자를 text로 추출하는 일종의 OCR 기법 응용이다.
- 지난 포스팅 링크는 https://jin-t.tistory.com/22
[웹스크래퍼 1탄] 이미지 기반 자동화 / 쿠팡 상품 크롤링(Crawling)-Python: openpyxl, selenium, pyautogui 이
<자동 URL접속-스크린샷-이미지파일 저장 프로그램> 1. 결과 동영상 - 성격이 급하신 분들을 위해 뭘 만들었는지 먼저 영상으로 만나보시라. 자동 URL접속-이미지캡쳐-저장 프로그램 2. 만들게 된
jin-t.tistory.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
1. 준비사항 Tesseract 설치 (MAC 사용자)
- 당신이 mac user라면 tesseract 설치시 아래를 참고하시기 바라며, 혹시 아니라면 필요한 내용만 참고하시길.
- 본론에 앞서 난 아래의 간단한 결론을 얻기 위해서 정말 많은시간 '삽질!'을 해왔다. 여기서는 tesseract를 이용한 문자 학습까지는 다루지 못했다.(현재 계속 시도 중인데, 아직은 완성하지 못해 추후 완성되면 별도로 포스팅 하겠다.)
(1) 먼저 내 환경이 가상환경이라면, 가상환경 들어가기 (Anaconda Navigator 활용편)
- 왼쪽 'Environments'에 들어가면 중간 아래쯤에 'Creat'가 보일것이다. 그곳을 눌러서 가상환경을 만들고싶은 이름 쓰고 엔터치면 가상환경이 만들어진다. (나는 'webscraping' 이라는 이름으로 만들었다.)
- 만든 가상환경 이름을 클릭하면 오른쪽에 오른쪽 방향의 삼격형이 보인다. 거기를 클릭하고 - Open Terminal을 클릭하면 왼쪽에 괄호로 가상환경 이름이 적인 terminal 창이 뜬다. (가상환경에 들어와있다는 뜻임, 왼쪽에 괄호가 없으면 가상환경 아니라 base(root)에서 작업하는 것임)
- 가끔 열심히 작업해놓고는 그 다음날 실행해서 안되는 이유가 가끔은 가상환경 설정이 안된 경우도 있다.

(2) homebrew로 tesseract 설치
- mac의 경우 환경설정을 도와주는 homebrew로 설치하는 것이 여러모로 좋다.
- 터미널 창에 : 'brew install tesseract'라고 치고 엔터를 치면 알아서 열심히 설치됨
(3) 언어팩(language package) 추가로 설치
- 터미널 창에 : 'brew install tesseract-lang'라고 치면 알아서 열심히 잘 설치됨
(4) 잘 설치됐는지 확인하는 방법
<tesseract 설치 확인 방법>
- 터미널 창에 : 'tesseract'라고 쳐보는 방법 - 아래 그림과 같이 나오면 OK
<언어팩 설치 확인 방법>
- 나는 한글과 영문과 숫자만 잘 인식하면 되었다. 한글만 확인해봤다. (아래 그림에서 'tess_test.png' 부분에 본인이 추출하고싶은 이미지 파일명을 기록하시면 됨)
- 아래와같이 'Detected xx diacritics'라고 뜨면 된것임. (물론 해당 output file을 열어보면 detected text가 보일거다.

위와같이 하면 되는데 가끔 다른 작업하느라고 이것저것 하다보면 내가 뭘 잘못했는지 안돌아갈 때가 있다. 그럴때 내가 해결했던 방법을 별도 포스팅해놓겠으니 확인해보시라.
2. 소스코드 (코드설명은 주석 확인바람)
#필요한 모듈들을 가져온다.
from PIL import Image
from pytesseract import *
import openpyxl
from glob import glob
#리스트 안에서 가장 큰 값을 찾는 함수
def max_in_list (x):
max_value = x[0]
for i in range(1, len(x)):
if max_value < x[i]:
max_value = x[i]
return max_value
#파일명 중에서 숫자만 받아와서 순서대로 리스트 안에 넣어놓는 코드
path = ('/web/')
files = glob(path + '*.png')
#리스트 안의 숫자가 순서대로 정렬되도록 하는 코드
i = 0
number_files = []
while i < len(files):
temp = files[i].replace(path,'').replace(' name_real.png','')
i = i + 1
number_files.append(int(temp))
#파일명 중 숫자가 순서대로 들어있는 리스트
count = sorted(number_files)
#tesseract로 불러온 사진을 text로 받아 리스트 만드는 코드
text_list = []
i = 0
j = 0
# while문을 count list안의 최대 숫자를 포함한 것까지 돌려야 함(그래야 엑셀파일과 매칭 됨)
## 이유는 - 이 코드의 목적은 엑셀파일에서 읽어온 링크 줄 옆에 텍스트로 변환한 값을 넣기 원하는 것이므로
while i <= max_in_list(count):
#이미지 파일명의 숫자가 '이전 숫자+1'이면 if문 실행 아니면 else문 실행
if i == count[j]:
img = Image.open(path + '%s name_real.png' %i)
#pytesseract로 이미지에서 추출된 text를 text라는 변수에 넣음 (첫번째 인자: 이미지, 두번째: 언어, 세번째:추출 방식)
text = image_to_string(img, lang='kor+eng',config='--psm 6')
print(text)
#CR LF Carrige Return (\r) Line Feed (\n) 가 안나오게 하려면 strip()을 사용하면 됨
temp = text.strip()
text_list.append(temp)
print('PROCEED ** i = ',i, ' count[j] = ',count[j])
i += 1
j += 1
else:
print('UNcounted ** i = ',i, ' count[j] = ',count[j])
#만약에 이미지 파일명 앞의 숫자가 '이전 숫자+1'이 아니라면 'EMPTY!'라는 문자를 text_list에 넣음
text_list.append('EMPTY!')
i += 1
print('==CORRECTION ** i = ',i, ' count[j] = ',count[j])
#엑셀파일 열기
wb = openpyxl.Workbook()
#원하는 시트 열기
ws = wb.active
#엑셀파일에 tesseract로 추출한 text들을 저장하는 코드
k = 1
while k <= len(text_list):
ws.cell(k,1).value = k-1
ws.cell(k,2).value = text_list[k-1]
k += 1
wb.save(path + 'text_list.xlsx')
print('All process is DONE!')
3. 코드 실행 결과
[왼쪽] 코드 실행 전 추출된 이미지 (지난 포스팅의 결과)
[오른쪽] 엑셀파일에 추출되어 엑셀파일에 저장됨
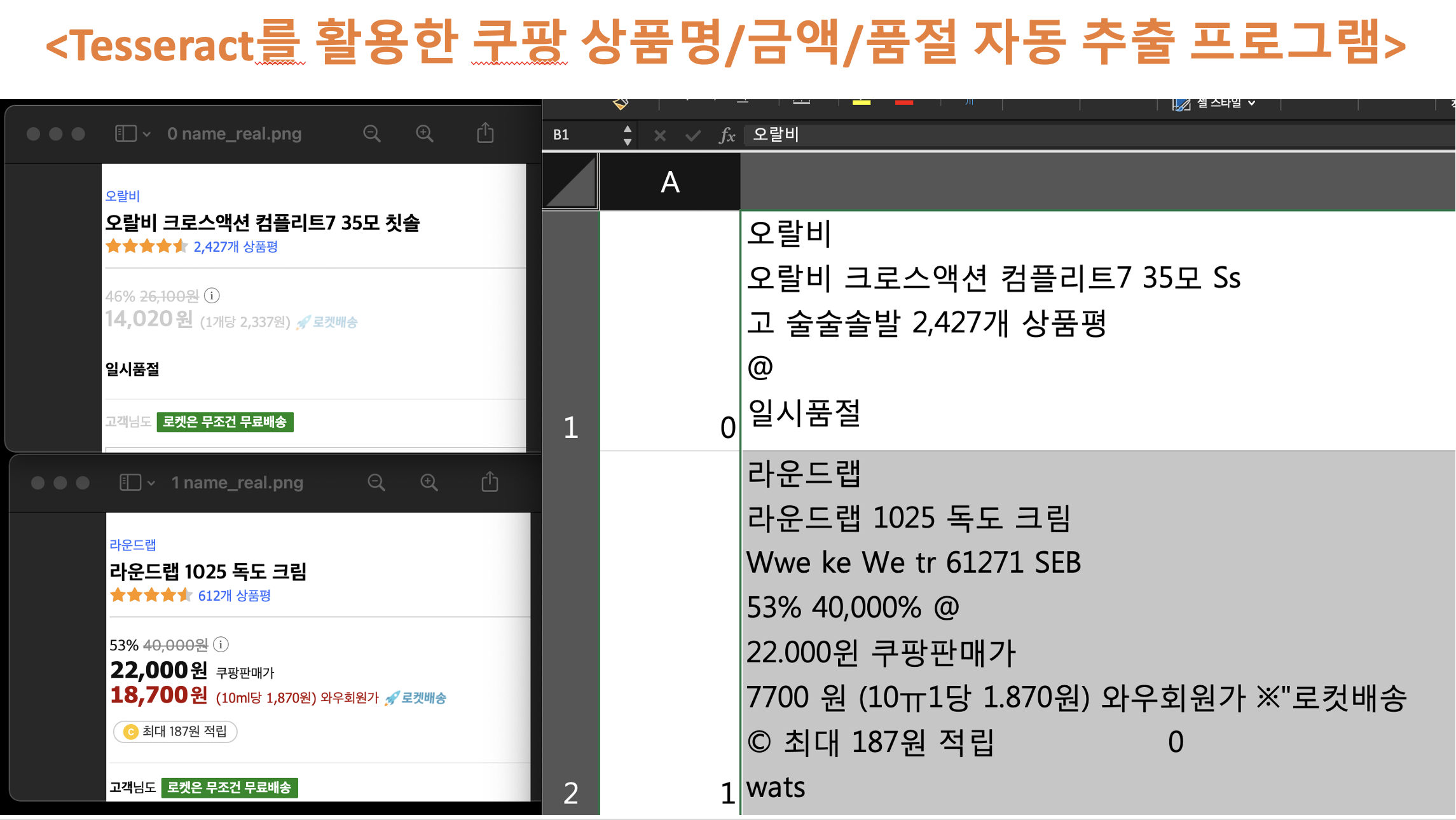
4. 결과에 대한 자체 평가
| 구분 | 내용 | 개선사항 |
| 상품명 | 대체로 알아볼 수 있을만큼 잘 추출됨 | 이대로도 만족함 |
| 가격 | 18, 콤마, 원 등의 문자를 잘 인식하지 못함 | 특정 문자들은 학습이 필요함 |
| 품절 인식 | '품절', '일시품절'이라는 글자는 잘 인식함 | 아주 만족함 (품절을 인식해주기만해도 좋음) |
'Programming' 카테고리의 다른 글
| [Fortran code convert to Python] 포트란 코드를 파이썬 코드로 바꾸기 (0) | 2023.01.08 |
|---|---|
| [그림보고 무조건 따라하기] 파이썬으로 PDF병합 프로그램 만들기 - PDF file merger using Python (PyPDF2 사용) (0) | 2022.05.24 |
| RINEX file study to make RINEX converter using Python 1탄! (0) | 2022.05.23 |
| [웹스크래퍼 1탄] 이미지 기반 자동화 / 쿠팡 상품 크롤링(Crawling)-Python: openpyxl, selenium, pyautogui 이용 (0) | 2021.05.28 |
| OpenPose로 motion estimation, 모션인식 (9) | 2020.08.16 |



