<자동 URL접속-스크린샷-이미지파일 저장 프로그램>

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
1. 결과 동영상
- 성격이 급하신 분들을 위해 뭘 만들었는지 먼저 영상으로 만나보시라.
2. 만들게 된 배경
최근 부업으로 쇼피를 시작했다. 쇼피에 물건을 100개정도 올렸는데, 첫 주문이 한달 반 만에 들어왔다.
- 그런데 문제는 : 가격을 할인하기 전 가격으로 올려야하는데, 할인 후 가격으로 올려서 할인의 할인이 되어 역마진으로 물건을 판매해야하는 상황이 됐다. 100개의 물건을 하나하나 보면서 내가 소싱한 사이트(쿠팡)와 대조해보며 가격과 그 외 정보를 맞춰봐야한다. 상품 올리는 것도 눈이 빠지게 올렸는데, 이것 또한 귀찮은 작업이다.
**엑셀파일 URL 목록 - 총 170개 정도 됨
*그래서! 요즘 공부중인 웹스크래핑을 이용하여 '내가 검색한 URL 목록에 접근-내용 읽어오기-엑셀에 저장' 하면 돼겠다 생각을 했지만!!!
쿠팡에 크롤링(스크래핑)을 하기 위해서 갖가지 노력을 기울여봤지만, 빈번히 실패하고말았다. (나만 안되는건지 아니면 다들 안되는건지 - 성공한 사람들 글들을 읽어보면 거의 1년전 올려진 글이었다.)
그냥 포기하고 하나하나 URL 들어가서 눈으로 확인하고 엑셀에 정리해야하나...라고 고민하던 찰나에 python 모듈 중 pyautogui와 selenium 그리고 tesseract을 알게되었고 두 기능을 이용하여 아래와같은 flow로 프로그램을 구성하게되었다.
3. 프로그램 구성(순서)
(1) 엑셀파일로 저장해둔 쿠팡 상품URL 목록을 불러옴
(2) 각 URL을 열어서 상품명, 금액 등 기본 정보가 있는 부분을 사진으로 캡쳐
(3) 캡쳐한 사진안의 글자들을 tesseract로 문자로 변환
(4) 변환된 문자를 엑셀파일에 정리
2. 소스코드
#아래와같은 모듈들이 필요하다. pip install 등을 통해서 미리 받으시길
import openpyxl
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pyautogui as pg
import time
#엑셀파일 열기 (WorkBook열기)
wb = openpyxl.load_workbook('URL_list.xlsx')
#원하는 시트 열기 ('Price Tool '이라고 된 WorkSheet열기)
ws = wb['Price Tool ']
#cell_link라는 빈 list 만들기 : 엑셀파일에 있는 url정보를 넣을 list
cell_link = []
i = 0
#엑셀 파일에 있는 url 정보들을 list로 받아옴
while i < 200: #정보가 200개 이하여서 일단 200이라고 했는데 (솔직히 최대 행 수만큼 하면된는데 만들다가 귀찮아서 그냥 200으로 함)
print(ws.cell(i+8,3).value)
#8번째 행, 3번째 열부터 시작해서 cell_link라는 list에 쌓음
cell_link.append(ws.cell(i+8,3).value)
i += 1
j = 0
#200 row까지 반복작업
while j < len(cell_link) :
#원하는 셀 정보 얻기
wc_url = cell_link[j]
#크롬으로 창 열어고 창 크기를 최대화하기 (크롬 드라이버를 다운받아서 이 파이썬 파일과 같은 폴더에 위치시켜야 함)
options = Options()
driver = webdriver.Chrome(executable_path='/chromedriver', chrome_options=options)
driver.set_window_size(1024,700) #크롬 창 열었을 때 사이즈
driver.get(wc_url)
time.sleep(2) #time sleep을 안주거나 너무 빨리하면(나는 2초로 했음) 웹창 띄우는 시간과 alert를 처리하는 시간 및 사진 저장하는 시간 순서가 안맞아서 에러남
#alert 처리하기 - 별도 화면 참고바람
try: #try 아래를 시도해보고 안되면 except로 감
result = driver.switch_to_alert()
print(result.text)
#alert 창 확인
result.accept()
#alert 창 끄기
#result.dismiss()
time.sleep(2) #여기도 time sleep 필요하고, 내가 2초로 한 이유는 더 빠르게 하면 타이밍이 안맞아서 에러남
except:
"There is no alert."
#사진 저장 경로
path = '/web/'
time.sleep(1)
#상품 이름 스크린샷 (여기서 pyautogui 모듈 사용)
##아래 screenshot 괄호 *첫번째 인자:저장할 경로와 파일명, *두번째 인자: 스크린샷 할 위치 (x,y,x에서 가로로 떨어진 위치, y에서 세로로 떨어진 위치)
pg.screenshot(path +'%s name_real.png' %j,region=(1084,746, (378)*2,(258)*2))
#열었던 창 닫음
driver.close()
j+= 1
파이썬 웹 스크래핑 2/e:수많은 데이터 사이에서 필요한 정보 수집하기
COUPANG
www.coupang.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
3. 소스코드 부가 설명
소스코드에서 주석으로 설명을 달았지만, 추가적인 설명이 필요한 부분들이 있어 아래 상세 설명을 해본다.
(1) path
- path 지정에 유의해야한다. 위 소스코드에서 몇번째 줄인지 말해주고싶지만, 숫자가 안나오는 관계로,
- path가 들어가는 곳이 3군데 있는데, 내가 사용한 path를 그대로 사용하고싶다면, 꼭 그 경로에 해당 파일을 넣어놓던가 (특히 chrome driver의 경우) 아니면 본인이 원하는 경로를 지정해서 사용하시라.
(2) pyautogui 의 screenshot 사용 시 화면 위치 (mac os x 사용자를 위해)
- 이거때문제 정말 고생 많이했는데, mac의 경우 '화면 해상도 x 2'를 해야 screenshot 위치를 원하시는 곳으로 잡을 수 있을거다. (중요!)
(3) alert 처리
- 위 영상에서도 보셨겠지만, 중간중간에 크롬 창 위쪽에 '데이터 처리에 실패했습니다. 다시 시도해 주세요.'라는 문구와 함께 alert창이 뜬다.
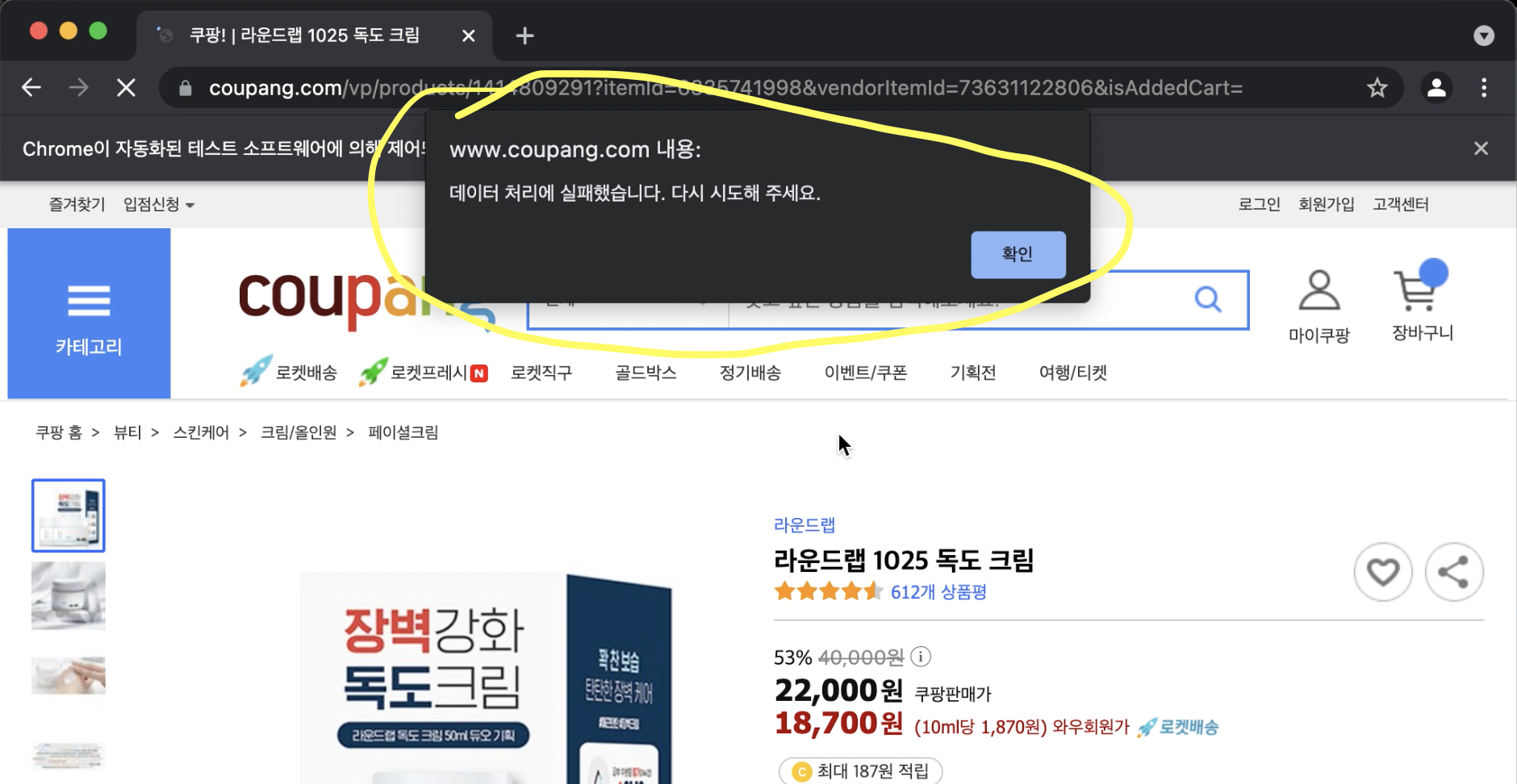
- 이 문제는 try: except: 로 처리하면 되는데, 위 소스코드에서 아랫쪽 부분에 있다. 주요 주의할 점! : time sleep을 중간에 집어넣었는데 너무 짧게 하거나, 없으면 alert를 처리할 시간을 주지않고 다음 라인을 실행하는 꼴이 되므로 꼭 time sleep을 넣어주고 적절한 시간 텀을 주어야한다. (나의 경우 2초를 주었다. 적당한 시간 텀으로 실험해보면서 바꿔도 좋다. - 난 몇번 해보다가 그냥 2초로 했다.)
다음 2탄에는 tesseract를 이용해서 여기서 저장한 사진들 안에 있는 텍스트파일들을 추출해서 엑셀파일에 저장하는 프로그램을 소개해보겠다.



